
[Paper Review] GLUCOSE-GeneraLized and COntextualized Story Explanations (2)
GLUCOSE의 지식 모형
1. 인과 관계의 10가지 차원
지난 포스팅에서 GLUCOSE는 10가지 차원으로 정의되었다고 설명했다. 논문에 따르면 이는 사람이 이야기를 이해하는 방법에 대한 인지 심리학 의 연구 결과에 근거한 것이라고 한다. 따라서 GLUCOSE는 이야기에서 선택된 사건 혹은 상태 X에 대하여, 그것이 일어나기 전 과 후 로 범주화하고, 각 범주는 5개의 차원을 포함해 구성되어 있다. 여기에 포함되는 차원은 다음과 같다.
- 사건, 시간선, 이야기의 흐름에 따른 개체의 위치
- 사건의 원인과 동기(motivation)
- 인물의 감정 변화
2. 반정형 추론 법칙
두번째 특징은 반정형 추론 법칙이다. 각 법칙은 “antecedent-connective-consequent” 의 형태를 가지며, antecedent과 consequent는 통사 슬롯(syntactic slots)을 채움으로서 구성된다. 이 통사 슬롯은 subject, verb, object(s), preposition(s) 등이 채워지게 된다.
반정형 추론 법칙은 또한 다음 두 가지로 구성되는데, 구체적 진술(a specific statement)과 일반 법칙(a general rule)이 바로 그것이다. 구체적 진술은 주어진 문맥에 근거한다는 뜻으로, GLUCOSE라는 논문의 제목에서 Contextualized 를 의미한다. 반대로 일반 법칙은 주어진 맥락을 넘어 다른 맥락에도 적용 가능하게끔 일반화 시키는 것이며, 논문 제목의 Generalized 부분에 해당한다.
이상의 설명으로 어느 정도 윤곽은 잡히지만 데이터를 실제로 보기 전에는 이게 무슨 말인지 완전히 이해하기 어렵다. 아래 이미지를 통해 구체적으로 알아보자.

위 이미지는 이 논문의 발표자료에서 발췌한 것이다. 이미지를 보면 먼저 상단의 이미지 속 색깔로 표시된 문장 X(Peppa turned her bike sharply)에 대하여 GLUCOSE 데이터셋이 어떻게 정의하는지 보여주고 있다. 좌측을 보면 차원(dimension)이 표기되어 있고 각각의 차원은 사건이 일어나기 전의 다른 사건, 감정, 동기, 위치 등을 묻고 있다. 이에 따라 “A car turned in front of her”, “Peppa want safety” 와 같은 식의 구체적 진술(specific statements)을 적고, 그 아래에 일반 법칙(general rule)을 작성한다. 이러한 방식으로 한 문장에 대해 풍부한 인과적 설명을 포함할 수 있게 되는 것이다.
영리한 방법이 아닐 수 없다. 바로 이 부분이 내가 이 논문에서 가장 인상적이었던 부분이다. 하나의 문장만으로 10개에 달하는 제각기 다른 문맥을 부여할 수 있다. 게다가 이는 인간의 머리 속 모형과도 상당히 유사하다고 볼 수 있다. 당장 우리도 ‘친구가 핸드폰을 샀다’와 같은 사건만으로도 ‘왜 샀어?’, ‘어디서 샀어?’ 등과 같은 질문이 자연스럽게 나오니까 말이다.
GLUCOSE Dataset
이제부터 글루코스 데이터셋을 어떻게 구축할 수 있었는지, 그 방법론을 살펴보자.
Source of stories
- 이 논문에서는
ROCStories(Mostafazadeh et al., 2016)라는 데이터셋을 기초로 데이터를 구축했다.ROCStories는 일상생활과 관련된 5개의 문장으로 이루어진 데이터인데, 사건의 인과관계가 시간적 흐름에 나타나고, 인과관계를 상식에 기반하여 추론할 수 있게 구성되어 있다는 특징이 있다. 한 예시를 가져오자면 다음과 같다.
ROCStories (Mostafazadeh et al., 2016)
| storyid | 8bbe6d11-1e2e-413c-bf81-eaea05f4f1bd |
|---|---|
| storytitle | David Drops the Weight |
| sentence1 | David noticed he had put on a lot of weight recently. |
| sentence2 | He examined his habits to try and figure out the reason. |
| sentence3 | He realized he’d been eating too much fast food lately. |
| sentence4 | He stopped going to burger places and started a vegetarian diet. |
| sentence5 | After a few weeks, he started to feel much better. |
- 위의 표에서 보이듯이 각각의 문장은 서로 시간의 흐름에 따라 구성되어 있으며, 마치 어린아이의 일기장같은 쉬운 어휘와 문장 구조를 사용하였다. GLUCOSE는 여기서 한 문장 X를 선택해, 그 앞 뒤의 문맥을 10가지 차원에 근거해서 새로 생성하는 작업으로 데이터셋이 구축되었다.
Data Acquisition Platform
- 데이터 수집 방법으로는 다른 여러 연구들과 같이 크라우드소싱을 사용했다. Amazon Mechanical Turk(Mturk)을 이용해서 일반 이용자와 함께 3단계로 이루어진 knowledge acquisition 파이프라인을 통해 데이터 수집이 이루어졌다.
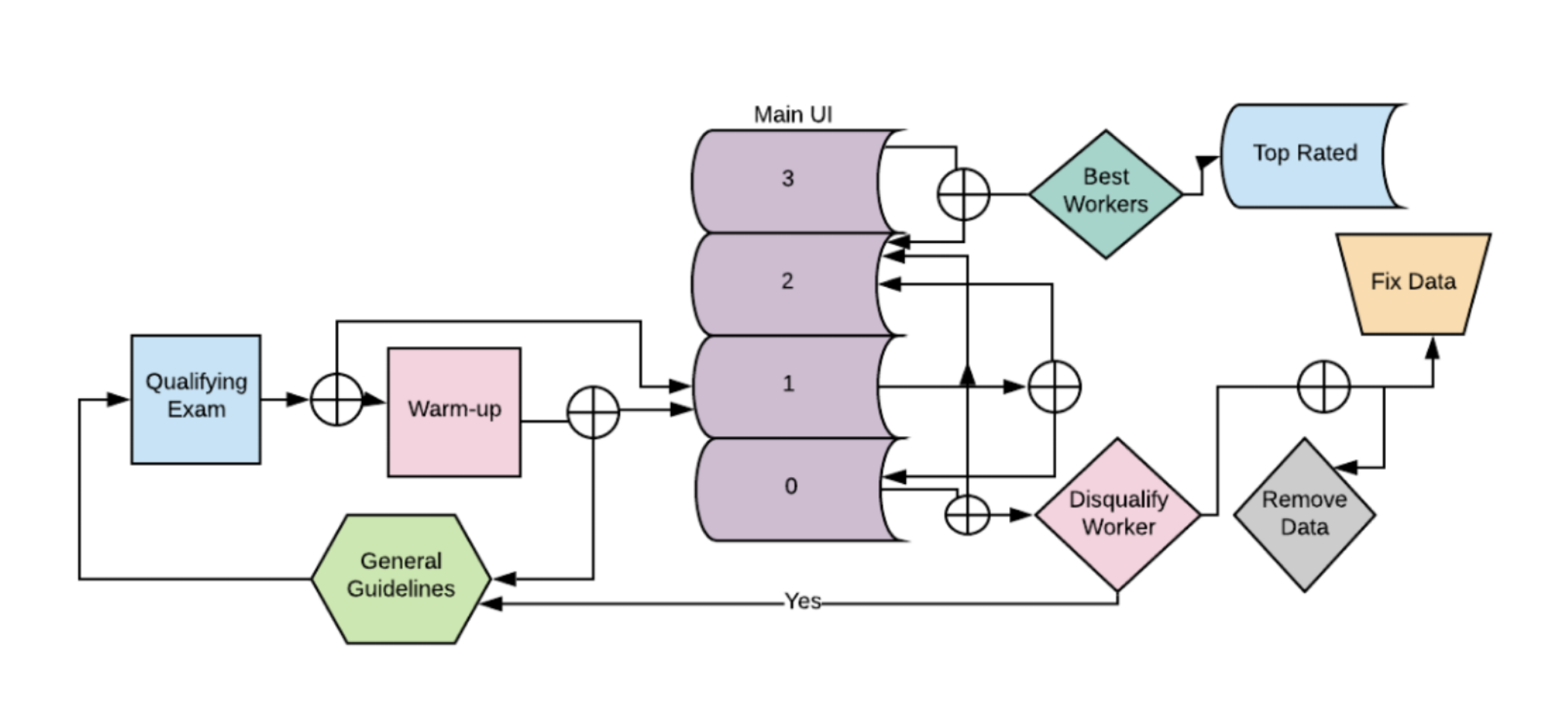
- 데이터 수집의 전체 파이프라인은 아래와 같다. 먼저 Qualifying Exam으로 지원자를 훈련시키고 Main UI에서 작업이 진행된다. 작업의 품질에 따라 0~3까지의 점수가 매겨지며, 최고점을 기록하는 작업자는 Best Workers에 분류된다. 반대로 성적이 부진한 작업자는 다시 가이드라인과 Qualifying Exam을 거치며 재교육시켜 다시 Main UI로 진입하게 된다. 이와 같은 방식으로 데이터의 품질을 확보했다.
통계
- GLUCOSE는 이와 같은 과정으로 약 670,000개의 주석을 확보하였다. 각각의 차원들에 대한 법칙의 분포는 아래의 bar plot과 같다. 1,6차원이 가장 많고, 9,10차원이 가장 적은 걸 알 수 있다.


다음으로 이를 어떻게 AI system에 통합시킬 수 있었는지는, 다음 포스팅에서 다루겠다.
Leave a comment