
[Paper Review] GLUCOSE-GeneraLized and COntextualized Story Explanations (3)
Emperical evaluation task
Q2. How to incorporate commonsense knowledge into the state-of-the-art AI systems?
지난 포스팅에서는 데이터 수집 방법론을 다뤘다. 이번에는 그렇게 해서 구축한 데이터셋을 가지고 어떤 일을 할 수 있을지 다뤄보려고 한다.
본 연구에서는 GLUCOSE 데이터를 가지고 모델을 평가할 수 있는 evaluation task 를 만들었다. 구체적으로 평가는 다음과 같다.
Task: S라는 짧은 이야기의 X라는 선택된 문장이 주어지고, 차원 d가 주어지면, specific and general forms의 explanation을 생성하기
실험에 쓰이는 데이터셋은 앞서 다룬 파이프라인에서 성적이 높은 Best worker들이 동의하면서, 이전에 모델에게 보여주지 않은(unseen) 이야기들로 선별되었다. 이 과정으로 총 500개의 이야기-문장(X) 쌍을 만들었고, 이들은 1에서 5까지의 차원으로 설명되어 있다(6-10차원을 포함시키지 않은 까닭은 1-5차원과 6-10차원이 단지 문장X의 앞 과 뒤 라는 차이밖에 없기 때문으로 보인다).
Evaluation은 human evaluation 과 automatic evaluation 을 모두 사용했다. 먼저 human evaluation 은 MTurk에서 진행되며, 3명의 Best worker들이 참여한다. 이들은 강조된 문장X을 먼저 읽고, X에 관한 GLUCOSE dimension에 대응하는 질문들을 읽은 후, 다른 시스템들에 의해 생성된 list of candidate answers을 보고, 각 candidate answer에 대해 four-point Likert scale 로 채점하게 된다.
다음으론 automatic evaluation 이다. Metric으로는 BLUE score 를 사용하였는데, 사실 BLUE score는 손쉬운 재현성으로 유명한 메트릭이 되었지만, 인간의 결과와의 상관관계에 있어서 여러 태스크들에서 약한 모습을 보인다는 약점이 있다. 이에 따라 먼저 human evaluation과의 상관관계를 살펴보았다. 본 연구에서 사용한 pairwise correlation analysis 의 결과를 보자면, 사람의 결과와 ScareBLEU 스코어 사이에 강한 correlation이 있음을 발견했다(Spearman = 0.891, Pearson = 0.855, and Kendall’s τ = 0.705, all with p-value < 0.001). 이에 저자들은 BLUE score로 test set의 결과를 report하는 데 쓰일 수 있다고 판단하였고, SacreBLUE score 를 최종 metric으로 선정했다. BLUE score에 대한 자세한 설명은 BLUE score게시글을 참조해보자.
Model
이제 모델을 선택할 차례이다. 사전훈련 언어 모델들(PLMs)을 불러와서 사용할 것인데, GLUCOSE task에 맞게 transfer learning을 시도할 것이다. 훈련의 train set과 dev set은 440,000개의 GLUCOSE annotation으로 이루어져 있고, 이건 3,360개의 이야기에 달하는 양이다. 모든 신경망 모델들은 multi-headed attention과 fully connected layers를 사용하는 transformer blocks을 인코더로 사용했다. 디코더로는 top-k sampling을 사용했는데, 이는 sampling 방법의 하나로 확률이 높은 k개의 단어에만 제한을 두어 엉뚱한 단어가 출현하는 것을 방지하는 방법이다. 자세한 설명은 top k sampling을 참조해보자. 평가를 위한 베이스라인 모델로는 GPT-2를 선택했다.
그런데 여기서 의문이 남는다. Sampling의 방법으로 top-k sampling을 선택한 이유가 충분히 설명된 것 같지 않달까. 많고 많은 방법들 중에서 왜 top-k sampling이 과연 최선이었을까? 가령 top-p (nucleus) sampling처럼, 누적 확률을 이용한 방법도 많이 이용되고 있는데 말이다. 여러 샘플링 기법들을 비교하는 방식을 썼다면 더 좋았을 것 같다는 생각이 든다.
다시 돌아와서, 모델 이야기를 더 해보자. 베이스라인 모델을 설정했으니, 이제 GLUCOSE 데이터로 훈련시킨 모델을 만들어야 한다. GLUCOSE 데이터는 연결사를 중심으로 antecedent consequent으로, 즉 선행문과 후행문으로 나뉘어져 있는 특징이 있다. 이에 따라 antecedent 혹은 consequent 하나에만 훈련시킨 모델 과, 양쪽 모두에 훈련시킨 모델 의 성능 비교를 보는 것도 의미가 있을 것이다. 여기서 전자를 One-sided generation(1S-LM) 이라 하고, 후자를 Full rule generation(Full-LM) 이라고 부르기로 한다. 각각은 베이스라인과 마찬가지로 GPT-2를 파인튜닝시켰지만, GPT-2는 transformer의 디코더 부분만을 사용한 모델이므로 성능의 차이를 보고자 transformer의 인코더와 디코더를 모두 사용한 T5 모델을 추가로 선정했다. T5 모델은 GLUCOSE의 양쪽 부분 모두에 훈련시켰다. T5도 최근 SOTA를 달성하며 각광받고 있는 모델인데, 우선 이름은 “Text-to-Text Transfer Transformer” (T5) neural network model 의 줄임말이다. T5는 모든 Task를 텍스트 기반으로 처리한다는 특징이 있다. 이 모델에 대해서는 T5에서 더 자세히 다뤄보겠다.
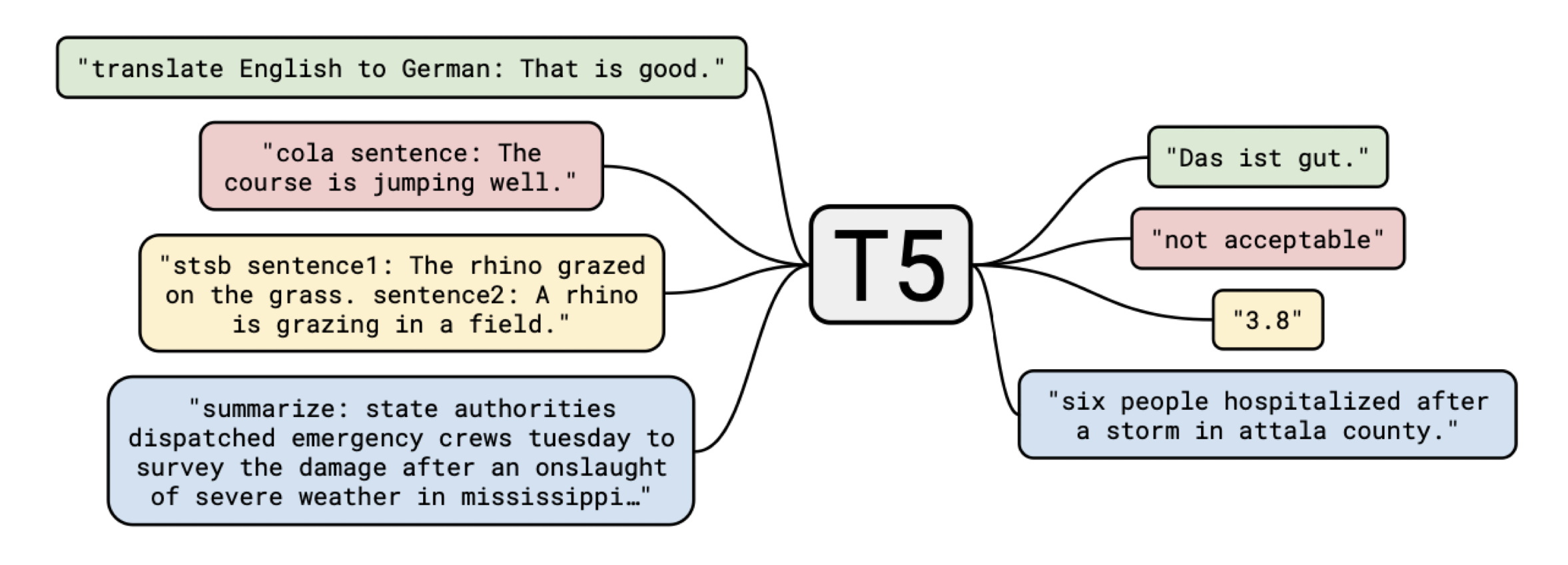
Results
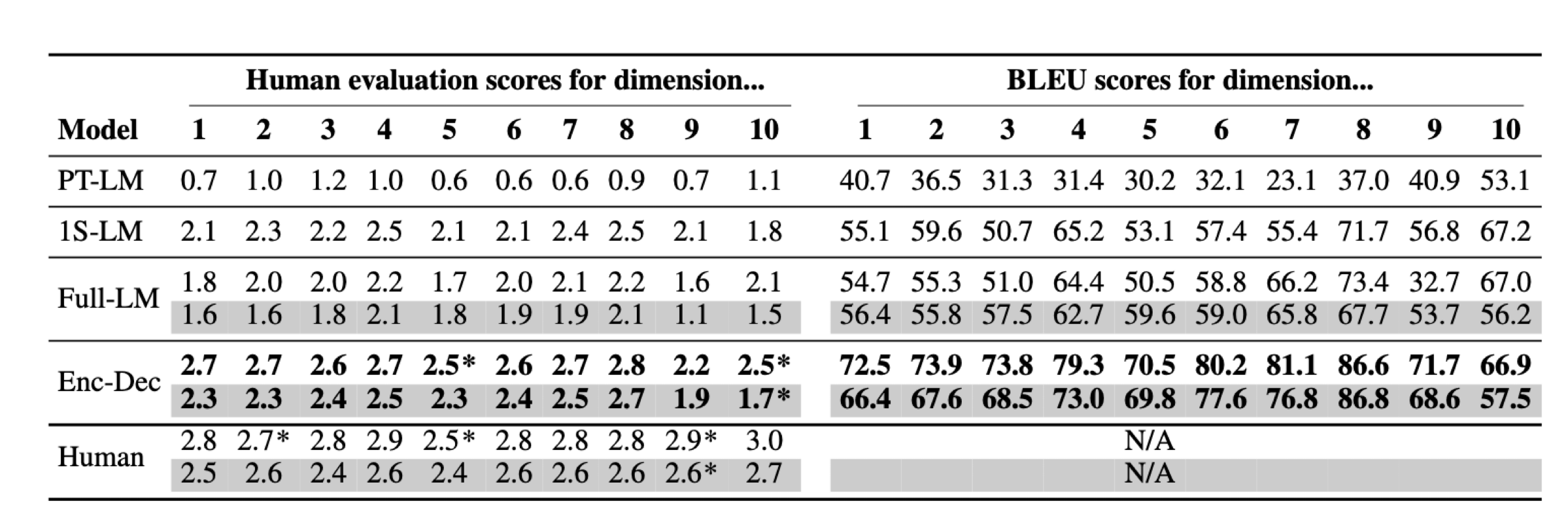
실험에 대한 결과표는 위와 같다. 결론부터 말하자면 베이스라인에 해당하는 사전학습 언어모델은 굉장히 낮은 성능을 보였으며 어떠한 기본적인 상식 추론도 해내지 못하였다. 표의 왼쪽은 각각의 모델 혹은 사람이 생성한 문장에 대한 human evaluation이다. 그리고 표의 오른쪽은 각각의 모델이 생성한 문장에 대한 blue score이다. human evaluation은 3점 만점이고, blue score는 100점 만점이다. 결과를 하나씩 보자면, 먼저 사전훈련 언어모델(PT-LM)은 굉장히 낮은 성능을 보이고 있는 것이 눈에 띈다. 1에서 10차원 중 human evaluation 값이 1이 넘는 것이 손에 꼽을 정도이다.
그런데 이러한 언어모델도 GLUCOSE 데이터로 훈련시키니 성능이 급격히 상승한 것도 눈에 띈다. GLUCOSE 데이터의 한쪽 면에만 훈련시킨 1S-LM만 봐도 평가 점수가 1점 이상 상승했으며, Full-LM의 경우에는 구체적 진술과 일반 법칙 모두를 생성해야 했기 때문에 어려운 task이었음에도 상당한 점수를 받았다. 가장 성능이 뛰어난 것은 T5 모델이다. 거의 2점 후반대의 점수를 받아 사람과 비교해도 크게 차이가 나지 않는 정도의 점수를 받았다. 이를 통해 사전훈련 언어모델이 GLUCOSE 데이터로 훈련되면, 인코더-디코더 모델 T5의 평가에서 보이듯이, 상식 추론에 굉장히 높은 성능을 휙득함을 알 수 있다.
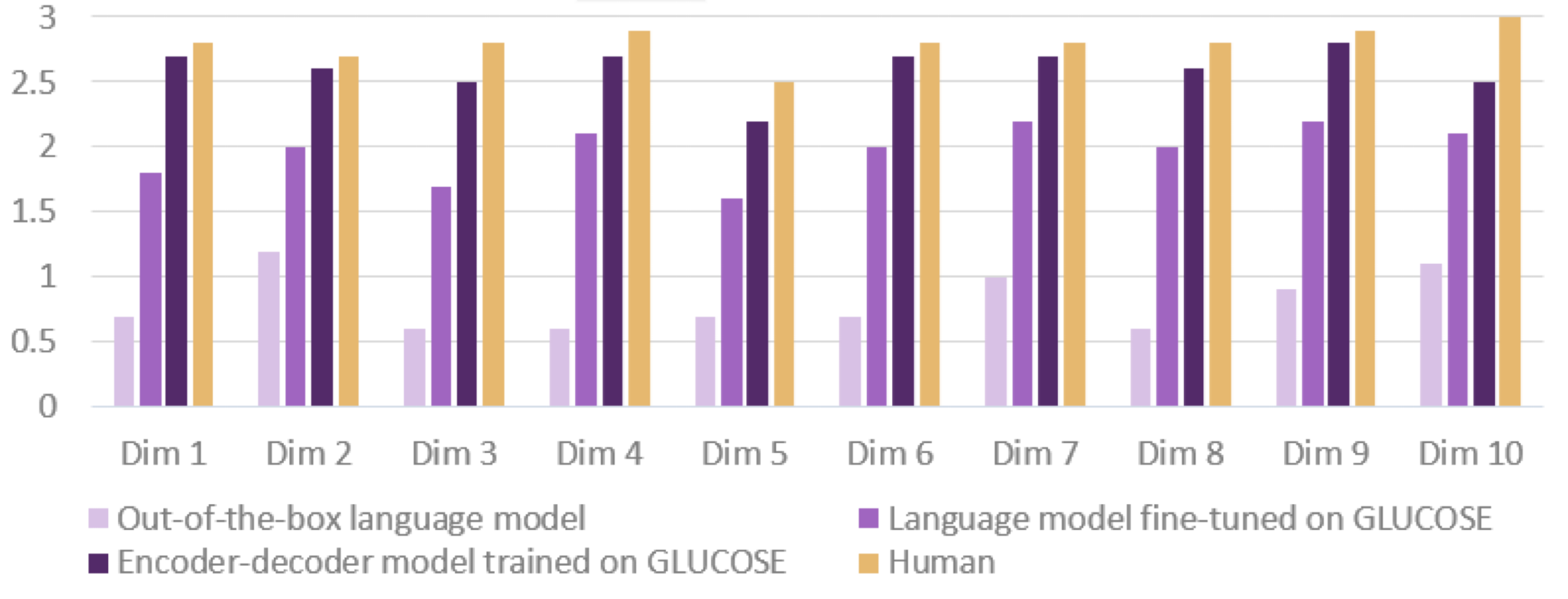
이상의 결과를 bar plot으로 시각화하면 위와 같다. 모든 차원에 있어서 GLUCOSE 데이터에 파인튜닝된 모델은 성능이 상당히 상승했으며, T5모델과 같이 인간과 비슷한 점수를 받기까지 했다.
Conclusion
We introduced GLUCOSE, a large-scale dataset of implicit commonsense knowledge, encoded as explanatory mini-theories grounded in a narrative context.
마침내 결론이다. GLUCOSE 데이터는 이야기에 근거하면서 사람이 세상을 해석하는 방법을 10가지 차원으로 정의하여 상식이라는 것을 데이터로 만들려고 했다. 심지어 이를 대규모로 크라우드소싱했다는 점에서 상당히 영리한 방법론을 구축했다고 볼 수 있다. 뿐만 아니라, 이를 evaluation task로까지 사용할 수 있도록 하여 GLUE benchmark와 같이, 모델을 평가하는 프레임워크를 만들었다. 상당히 인상적인 논문이었고, ‘EMNLP에 개제되는 논문은 이런 것이구나…‘라는 생각을 들게 한 논문이다.
AI라 불리는 여러 모델들이 우후죽순처럼 나오고 있다. 그러나 BERT와 같이 수직적인 성능 향상을 보이기 보다, 그저 수평적 발전만을 반복하고 있는 현실에 회의적인 시선도 있다. 그것도 모델 아키텍쳐를 손보는 것이 아니라 파라미터 수만 늘려가고 있는 추세에, 이러한 모델들을 평가할 수 있는 evaluation 프레임워크가 나오는 것은 다행스러운 일이다. 모델이 아무리 많아도, 그 모델들이 무엇을 할 수 있는지를 알지 못한다면 아무런 소용이 없다고 생각한다. 앞으로도 이런 상식 추론에 대한 평가 시스템이 많이 출현하기를 바래본다.
Leave a comment