
[project] 코로나19 신문기사 워드임베딩-국내
본 포스팅은 2021 ELSOK 온라인 춘계학술대회에서 발표한 내용을 재구성한 것이다.
1. 들어가며
코로나바이러스 감염증19, 이하 코로나19 는 2019년 12월 발견되어, 2020 년 3월 WHO에 의해 판데믹으로 선언되고 지금까지도 전 세계적으로 영향을 끼치고 있다. 어느새 2년을 지나 3년이 가까워지고 있는 오늘날, 우리는 조금씩 일상을 되찾아가고 있지만 그렇다고 ‘코로나 이전’과 ‘코로나 이후’가 절대 같지 않음을 모두가 안다. 우린 이제 새로운 표준, ‘New nomal’의 시대를 살고 있고, 그런 점에서 코로나19는 사람들의 일상을 완전히 변화시켰다.
그렇다면, 이러한 변화를 전산적으로 알아볼 방법은 없을까? 여기서 이 프로젝트, '코로나19 신문기사 워드임베딩'이 시작되었다. 먼저 국내 신문기사를 워드임베딩한 결과를 살펴보고, 이후 영어 신문기사를 대상으로도 포스팅을 이어갈 예정이다.
2. 연구의 목적
- 코로나19가 발발한 이후 1년 간 한국에서 발행된 텍스트 데이터로 이루어진 코로나19 코퍼스를 대상으로 워드임베딩(word embedding)을 통해 분석한다.
- 실증적 언어 데이터인 코퍼스를 이용하여 코로나19 사태에 대한 사용 기반(usage-based) 접근법을 시도
3. 연구 방법론
코로나바이러스에 관한 정보는 대부분 텍스트 데이터의 형태로 배포되고 있다. 그중에서 특히 신문기사는 주요 이슈와 사회적 반응을 가장 객관적이고 빠르게 전달하는 매체이다. 따라서 코로나19 관련 기사만 모은 코퍼스를 대상으로 워드임베딩을 시도한다.
3-1. 코퍼스(corpus)
한국어 코로나 바이러스 코퍼스 :고려대학교 언어정보연구소 계산의미론 연구실에서 자체적으로 수집한 것을 사용했다. 2020년 한 해 동안 발행된 151만 개의 네이버 뉴스 기사를 크롤링하여 구축된 코퍼스이다.
3-2. 데이터 전처리
먼저 Mecab 형태소 분석기를 사용했다. Mecab이 기본적으로 제공하는 단어 사전은 코로나19 관련 뉴스기사에서 출현하는 어휘들을 모두 포함하지 못하므로, 사용자 단어 사전에 10,570개의 어휘를 추가했다. 이후 국립국어원 선별 ‘가장 많이 사용되는 한국어 용어 모음집’에 근거하여 형태소 분석을 시도하고, 불용어(stop words)를 제거했다. 마지막으로 기호 및 외국어로 나오는 형태소 또한 제거했다.
3-3. 워드 임베딩(word embedding)
워드임베딩은 자연어를 컴퓨터가 이해할 수 있도록 벡터로 표상시키는 방법이다. 즉 자연어를 밀집 표상(dense representation)하는 방법을 일컫는다. 워드임베딩의 결과로는 임베딩 벡터(embedding vector) 값을 얻게 된다. 워드 임베딩의 방법으로는 대표적으로 Word2Vec이 있고, FastText나 Glove와 같은 방식도 많이 쓰이고 있다. 워드 임베딩과 그 종류에 대한 자세한 설명은 워드 임베딩 게시글에서 다룬다.
워드임베딩은 비슷한 위치에 등장하는 단어들은 그 의미도 유사할 것이라는 ‘분포 가설(distributional hypothesis)’에 근거하고 있는데, 이에 따라 자신과 공기(co-occur)하는 단어들의 상대적 위치를 기반으로 단어들이 벡터화된다. 이 프로젝트에서 사용된 워드임베딩 기법은 Word2Vec이다. Word2Vec은 단어를 벡터화할 때 단어의 문맥적 의미를 보존한다는 특징이 있어, 동음이의어 간의 구별이 가능해진다. 여기서는 중심 단어에서 주변 단어를 예측하는 skip-gram 기법을 사용하였고, vector size는 300으로 설정하였다. 주변 몇 개까지의 단어를 고려하는지 설정하는 window size는 5개의 단어까지로 설정하였다. 마지막으로, 최소 빈도 10번 이상의 단어들만 고려하도록 하였다.
3-4. 시각화
고차원의 표상을 저차원으로 변환하여 사람이 이해할 수 있도록 하는 것이 시각화의 목표이다. 이 프로젝트에서는 t-SNE(t-distributed Stochastic Neighbor Embedding) 기법을 사용하였다. 이는 고차원의 임베딩 모델을 저차원으로 축소하는 동시에 이웃 벡터간의 거리를 최대한 보존하는 시각화 방법이다. 아까 설정한 300차원의 모델을 2차원으로 선형변환 압축하였고, 단어의 의미는 그대로 보존하도록 하였다. 이를 통해 단어간의 의미적 유사성을 효과적으로 볼 수 있었다. 시각화는 다음의 코드로 진행하였다.
단계 1: 한국어 모델 불러오기
with open("./covid_ko_w2v(tokens).pkl","rb") as fr:
model = pickle.load(fr)
from sklearn.manifold import TSNE
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
from gensim.models import KeyedVectors
from IPython.display import set_matplotlib_formats
import numpy as np
import matplotlib.font_manager as fm
from collections import Counter
import plotly
import plotly.graph_objs as go
미리 전처리와 토크나이징을 진행시키고 word2vec으로 훈련시킨 모델을 pickle 형식으로 저장시켰었다. 이를 불러오고 필요한 라이브러리를 설치한다.
단계 2: 키워드 설정
def append_list(sim_words, words):
list_of_words = []
for i in range(len(sim_words)):
sim_words_list = list(sim_words[i])
sim_words_list.append(words)
sim_words_tuple = tuple(sim_words_list)
list_of_words.append(sim_words_tuple)
return list_of_words
input_word = '대통령, 시위, 사재기, 마스크, 백신, 격리, 혐오, 지원금, 여행, 실직' #알아보고자 하는 키워드 설정
user_input = [x.strip() for x in input_word.split(',')]
result_word = []
for words in user_input:
sim_words = model.wv.most_similar(words, topn = 20)
sim_words = append_list(sim_words, words)
result_word.extend(sim_words)
similar_word = [word[0] for word in result_word]
similarity = [word[1] for word in result_word]
similar_word.extend(user_input)
labels = [word[2] for word in result_word]
label_dict = dict([(y,x+1) for x,y in enumerate(set(labels))])
color_map = [label_dict[x] for x in labels]
그 후 알아보고 싶은 키워드를 설정해야 한다. 나는 ‘대통령, 시위, 사재기, 마스크, 백신, 격리, 혐오, 지원금, 여행, 실직’이라는 키워드들을 설정했다. 또한 이들과 벡터 공간에서 비슷한 위치에 출현하는 단어는 20개까지 출력하도록 설정했다.
단계 3: 2차원 시각화
def display_tsne_scatterplot_2D(model, user_input=None, words=None, label=None, color_map=None, perplexity = 0, learning_rate = 0, iteration = 0, topn=20, sample=10):
if words == None:
if sample > 0:
words = np.random.choice(list(model.index_to_key), sample)
else:
words = [ word for word in model.wv ]
word_vectors = np.array([model.wv[w] for w in words])
two_dim = TSNE(n_components = 2, random_state=0, perplexity = perplexity, learning_rate = learning_rate, n_iter = iteration).fit_transform(word_vectors)[:,:2]
data = []
count = 0
for i in range (len(user_input)):
trace = go.Scatter(
x = two_dim[count:count+topn,0],
y = two_dim[count:count+topn,1],
text = words[count:count+topn],
name = user_input[i],
textposition = "top center",
textfont_size = 15,
mode = 'markers+text',
marker = {
'size': 15,
'opacity': 0.8,
'color': 2
}
)
data.append(trace)
count = count+topn
trace_input = go.Scatter(
x = two_dim[count:,0],
y = two_dim[count:,1],
text = words[count:],
name = 'input words',
textposition = "top center",
textfont_size = 15,
mode = 'markers+text',
marker = {
'size': 15,
'opacity': 1,
'color': 'black'
}
)
data.append(trace_input)
# Configure the layout
layout = go.Layout(
margin = {'l': 0, 'r': 0, 'b': 0, 't': 0},
showlegend=True,
legend=dict(
x=1,
y=0.5,
font=dict(
family="Malgun Gothic",
size=25,
color="black"
)),
font = dict(
family = " Malgun Gothic ",
size = 15),
autosize = False,
width = 1280,
height = 1280
)
plot_figure = go.Figure(data = data, layout = layout)
plot_figure.show()
폰트 사이즈와 같은 디자인적 요소를 설정한 후, 2D로 출력하기로 한다.
4. Result
마지막으로 아래의 코드를 실행시키면 t-SNE 시각화가 완료된다.
display_tsne_scatterplot_2D(model, user_input, similar_word, labels, color_map, 20, 500, 10000)
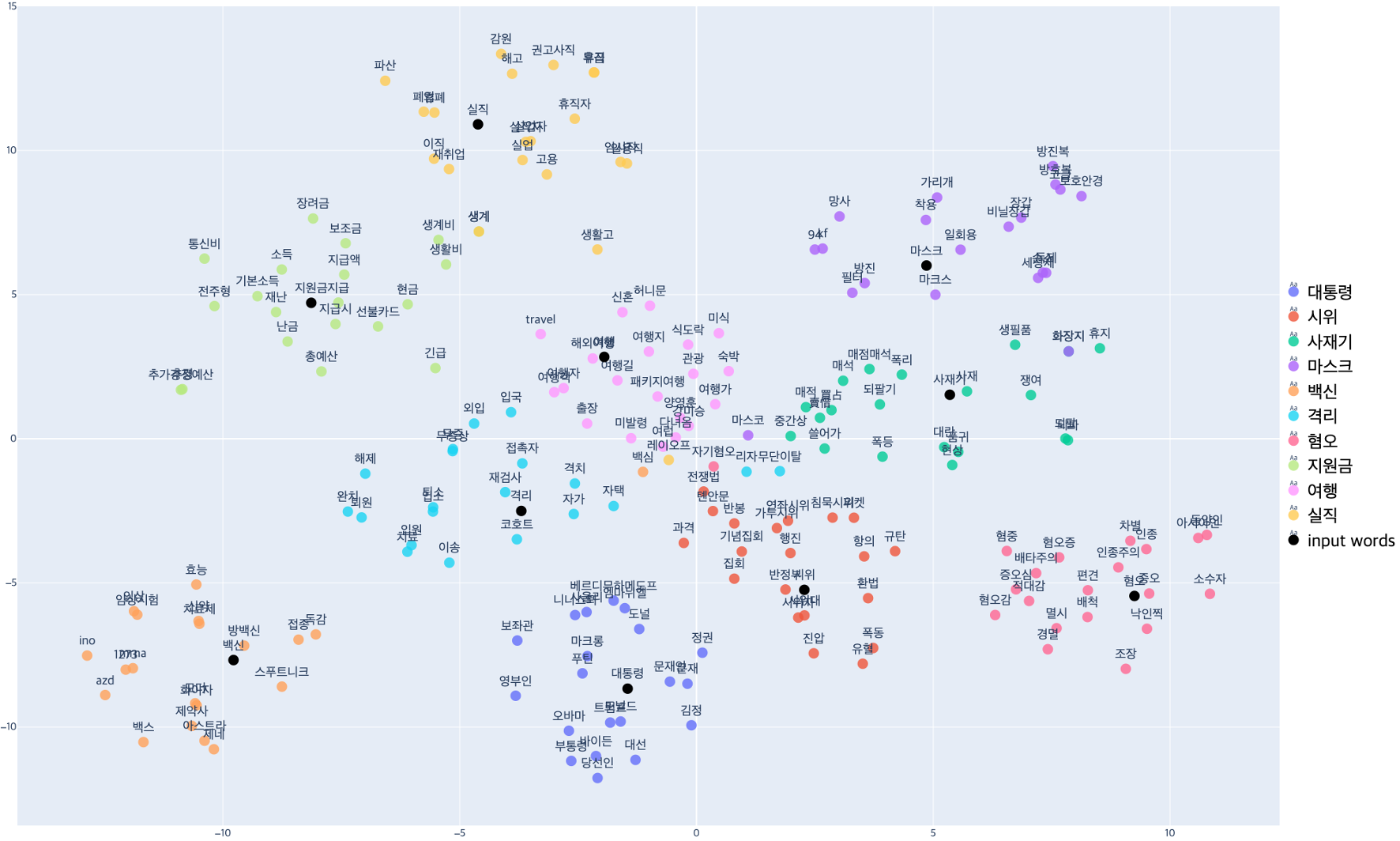
먼저 t-SNE의 시각화 결과에서 가로와 세로는 단어들의 벡터 좌표값인데, 이 벡터값은 t-SNE 특성상 고정되어 있지 않다. 따라서 벡터값의 절대적 위치보다는 키워드끼리의 방향이 어떤지, 무엇이 무엇과 가까운지 등과 같은 분포적 양상을 봐야 한다. 먼저 여기서 키워드를 둘러싸는 단어들이 등장하는데, 이 단어들은 원 키워드와 코사인 유사도(cosine similarity)가 높은 , 즉 의미적으로 유사한 상위 20개 단어들이 출현하도록 설정했다. 코사인 유사도의 분산이 크다면 가운데와 같이 키워드와 공기어들은 넓게 퍼지게 되고, 작다면 ‘마스크’ 클러스터와 같이 좁게 밀집하게 되는 것을 확인할 수 있다.
결과값에서 흥미로운 것은 ‘사재기’와 ‘마스크’가 같은 방향에 위치한다는 점이다. 실제로 2020년 초에 마스크 품귀 사태를 반영한 모습이다. 또한 ‘여행’과 ‘격리’도 같은 위치에 등장한다. ‘시위’와 ‘혐오’가 비슷한 방향에서 클러스터를 이루는 것도 눈 여겨 볼 만하다. ‘실직’과 ‘지원금’이 같은 방향에 위치한 것도 찾아볼 수 있다.
이번에는 Word2Vec을 통해 cosine 유사도를 살펴보자. 먼저 살펴볼 키워드는 ‘시위’ 키워드이다. 아래 표를 보자.
| Word | Similarity |
|---|---|
| 반정부 | 0.5868 |
| 시위대 | 0.5597 |
| 집회 | 0.5427 |
| 전쟁법 | 0.5036 |
| 톈안문 | 0.4992 |
| 폐렴 | 0.4958 |
| 기념집회 | 0.4937 |
| 시위자 | 0.4911 |
| 가두시위 | 0.4883 |
| 플로이드 | 0.4650 |
위와 같이 ‘시위’ 키워드에는 ‘반정부’, ‘집회’, ‘가두시위’ 같은 단어들이 높은 cosine 유사도를 보이며 등장하고 있다. 또한 ‘플로이드’라는 단어를 통해 BLM 시위의 정보도 찾아볼 수 있다.
| Word | Similarity |
|---|---|
| 증오 | 0.5885 |
| 아시아인 | 0.5520 |
| 인종 | 0.5416 |
| 낙인찍 | 0.5364 |
| 인종주의 | 0.5359 |
| 소수자 | 0.5293 |
| 동양인 | 0.5181 |
| 혐중 | 0.5067 |
| 편견 | 0.5037 |
| 폐렴 | 0.5002 |
다음으로 볼 것은 ‘혐오’ 키워드이다. 아래의 표를 보자.
| Word | Similarity |
|---|---|
| 증오 | 0.5885 |
| 아시아인 | 0.5520 |
| 인종 | 0.5416 |
| 낙인찍 | 0.5364 |
| 인종주의 | 0.5359 |
| 소수자 | 0.5293 |
| 동양인 | 0.5181 |
| 혐중 | 0.5067 |
| 편견 | 0.5037 |
| 폐렴 | 0.5002 |
여기서는 ‘아시아인’, ‘인종’, ‘동양인’, ‘혐중’ 등 코로나19 사태로 인해 등장한 여러 국가/인종 관련 이슈가 나타나고 있다. 특히 2020년 동안에는 ‘아시아인 = covid’라는 편견이 외국에 퍼져있어서 특히나 아시아인에 대한 증오범죄가 우려되던 상황이었다. 이러한 모습마저 Word2Vec이 잘 잡아낸 것 같이 보인다.
5. 나가며
지금까지 2020년 한 해동안의 코로나19 관련 한국어 신문기사를 대상으로 Word2Vec을 시도한 결과를 살펴보았다. 코로나19는 전세계적으로도 유례없는 상황이었던 만큼, 이 시기에 발행되었던 텍스트 데이터에도 그 위기와 혼란을 찾아볼 수 있었다. 이제 이 길고 길었던 코로나19의 터널의 끝이 보이는 요즘, 지난 2년 동안 우리가 어떤 터널을 지나왔는지, 어떤 갈등과 혐오를 남겨두고 왔는지 다시한번 돌아볼 때가 아닌가 하는 생각이 든다.
다음으로 포스팅하려는 것은 미국 신문기사를 대상으로 한 Word2Vec이다. 원래는 미국와 한국의 신문기사 워드임베딩을 함께 비교, 분석하였지만, 블로그 포스팅용으로는 이를 나누는 것이 좋을 것 같았다. 다음 포스팅에서 마저 이어가 보자.
Leave a comment