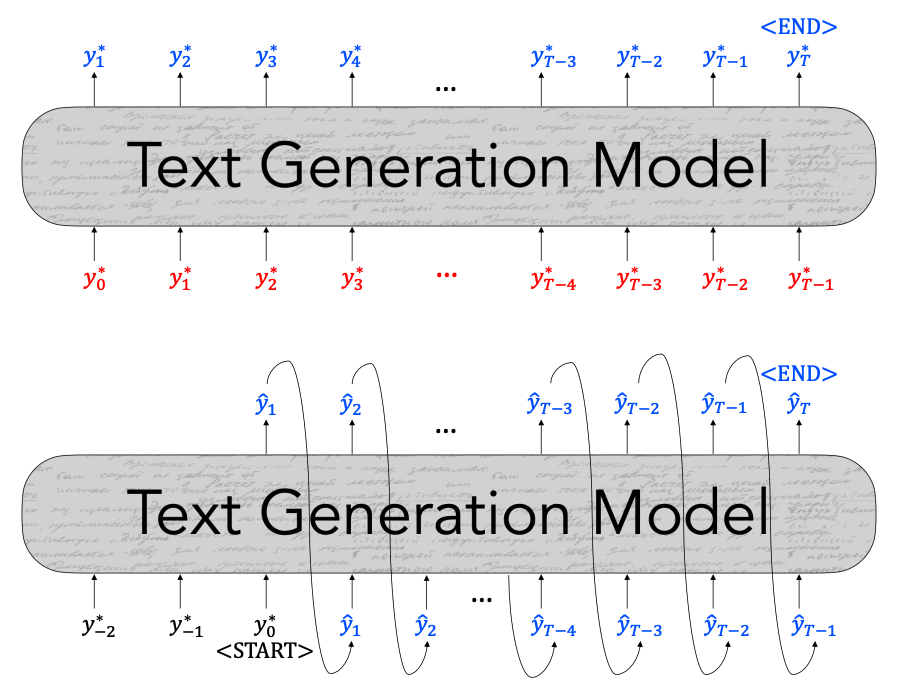
Exposure bias
- Training with Teacher forcing leads to exposure bias at generation time
- During training, our model’s inputs are gold context tokens from real, human-generated texts.
$$L_{MLE} = -logP(y_t^* | {\color{red}{y^*}_{<t}})$$
- At generation time, our model’s inputs are previously–decoded tokens.
$$L_{dec} = -logP(\hat{y}t | {\color{blue}\hat{y}{<t}})$$
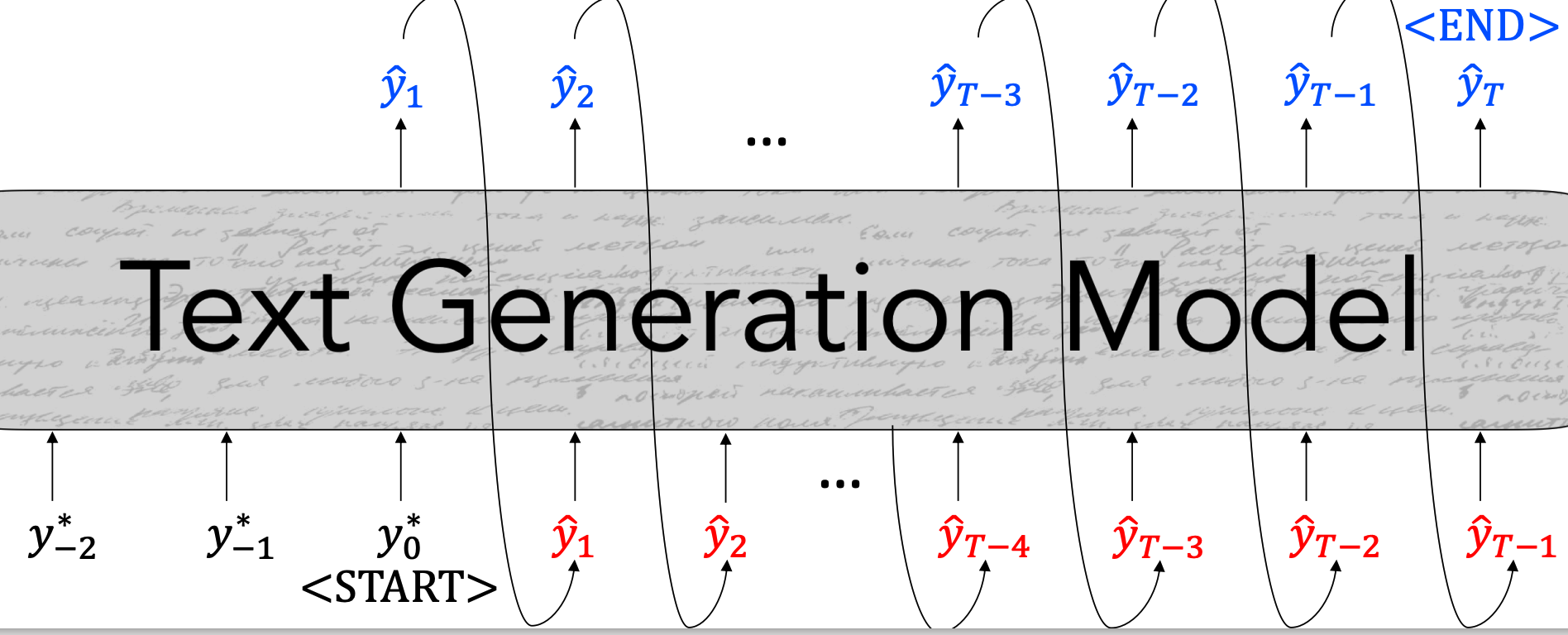
- At generation time, our model’s inputs are previously–decoded tokens.
$$L_{dec} = -logP(\hat{y}t | {\color{blue}\hat{y}{<t}})$$
- Exposure Bias Solutions
- Scheduled sampling (Bengio et al., 2015)
- Dataset Aggregation (DAgger; Ross et al., 2011)
- Sequence re-writing (Guu*, Hashimoto* et al., 2018)
- Reinforcement Learning: cast your text generation model as a Markov decision process
- State $s$ is the model’s representation of the preceding context
- Actions $a$ are the words that can be generated
- Policy $\pi$ is the decoder
- Rewards $r$ are provided by an external score
- Learn behaviors by rewarding the model when it exhibits them.
- REINFORCE: Basic
- Sample a sequence from your model
- Next time, increase the probability of this sampled token in the same context.
- …but do it more if I get a high reward from the reward function.
$$L_{RL} = -\sum_{t=1}^T {\color{red}r(\hat{y_t})}logP(\hat{y}t | y^*;{\color{blue}{\hat{y_t}}{<t}})$$
Exposure bias는 teacher forcing을 사용하는 최대 우도 추정(MLE) 훈련에서 발생하는 훈련과 추론의 불일치 문제를 말합니다.
- 이 문제는 자연어 생성(NLG) 모델 훈련의 중요한 문제로 간주되어 왔습니다. Exposure bias를 피하고 제거하기 위해 많은 알고리즘이 제안되었지만, 이 문제가 얼마나 심각한지 정량적으로 측정하는 방법은 아직 잘 알려져 있지 않습니다.
Exposure bias를 해결하기 위한 몇 가지 방법은 다음과 같습니다.
- Scheduled sampling: 훈련 과정에서 일정한 확률로 실제 출력을 입력으로 사용하는 방법입니다.
- Reinforcement learning: NLG 모델을 에이전트로 간주하고 보상 함수를 정의하여 학습하는 방법입니다.
- Professor forcing: 훈련과 추론 시에 동일한 순환 상태 분포를 유지하기 위해 적대적 손실을 사용하는 방법입니다.
- Variational inference: NLG 모델의 잠재 변수를 도입하여 확률적으로 샘플링하고 근사적인 사후 분포를 학습하는 방법입니다.
Reinforcement learning이 exposure bias 해결 방법이 될 수 있는 이유는 다음과 같습니다.
- Exposure bias란 teacher forcing 방식으로 훈련된 언어 모델이 추론 단계에서 훈련 코퍼스에 없는 자신의 이전 예측에 의존하는 문제를 말합니다.
- Reinforcement learning은 언어 모델의 예측에 대해 외부 보상을 주어 학습을 가이드하는 방법입니다.
- Reinforcement learning은 언어 모델이 자신의 예측에 따라 보상을 받기 때문에 exposure bias를 줄일 수 있습니다.
- Reinforcement learning은 또한 언어 모델의 다양성과 일관성을 향상시킬 수 있습니다.