On Cross-Dataset Generalization in Automatic Detection of Online Abuse
Reference
Nejadgholi, I., & Kiritchenko, S. (2020). On cross-dataset generalization in automatic detection of online abuse. arXiv preprint arXiv:2010.07414.
# Research Questions
Test and training sets were created for each dataset by performing a stratified split of 20% vs 80%, with the larger part used for training the models. The training sets were further subdivided, keeping 1/8 shares of them as separate validation sets during development and fine-tuning of the hyper-parameters.
- Fine-tuning에서의 일반적인 방법을 말하고 있다. 전체 데이터를 label 분포를 유지한 채로
train,test으로 나누고, 이후train에서validation을 다시 나눈다. 특히test데이터셋은 훈련에 쓰이지 않는데, 이후 학습한 모델의 일반화 성능을 평가할 때 사용한다. 그래서test데이터셋에서 성능이 잘 나온다면, 해당 모델이 다른 데이터셋에서도 성능이 잘 나올 것이라는 가설을 세울 수 있다. - 그러나 본 논문은 이 가설에 의문을 제기한다.
(…) the aim here, in contrast, was to see how well the best models (that may have learnt some dataset-specific biases) performed on other datasets. This was done to investigate how well state-of-the-art systems perform in a real-life scenario, i.e., when exposed to data from other domains, with the hypothesis that a model trained on one dataset that exhibits comparatively reasonable results on other datasets can be expected to generalise well.
- 이 논문의 목적은 그렇게 한 데이터셋을 잘 학습한(아마도 그 데이터셋에 내재한 편향도 잘 학습한) 모델이 다른 데이터셋에 얼마나 성능이 좋은지 보는 것이다. 이건 실제 세계에서의 상황과 유사한데, 모델은 결국 다른 도메인에서 생성된 데이터에 노출될 수 밖에 없기 때문이다.
- 이를 통해 ‘한 데이터셋을 잘 학습하여 좋은 성능을 내는 모델이라면, 다른 데이터셋에도 잘 일반화를 할 수 있을 것‘이라는 가설을 실제로 확인해보는 것이다.
# 실험 방법
To explore how well the Toxic class from the Wiki-dataset generalizes to other types of offensive behaviour, we train a binary classifier (Toxic vs. Normal) on the Wiki-dataset (combining the train, development and test sets) and test it on the Out-of-Domain Test set. This classifier is expected to predict a positive (Toxic) label for the instances of classes Founta-Abusive, Founta-Hateful, Waseem-Sexism and Waseem-Racism, and a negative (Normal) label for the tweets in the Founta-Normal class. We fine-tune a BERT-based classifier (Devlin et al., 2019) with a linear prediction layer, the batch size of 16 and the learning rate of 2 × 10−5 for 2 epochs.
- 저자들은 Wiki-dataset으로 훈련한 모델이 다른 데이터셋에 얼마나 잘 일반화하는가를 보기 위해, binary classifier를 wiki-Dataset으로 훈련시키고 ‘도메인 외 테스트셋(the Out-of-Domain Test set)’ 에 이를 테스트 했다. 모델은 BERT를 사용했다.
# 실험 결과
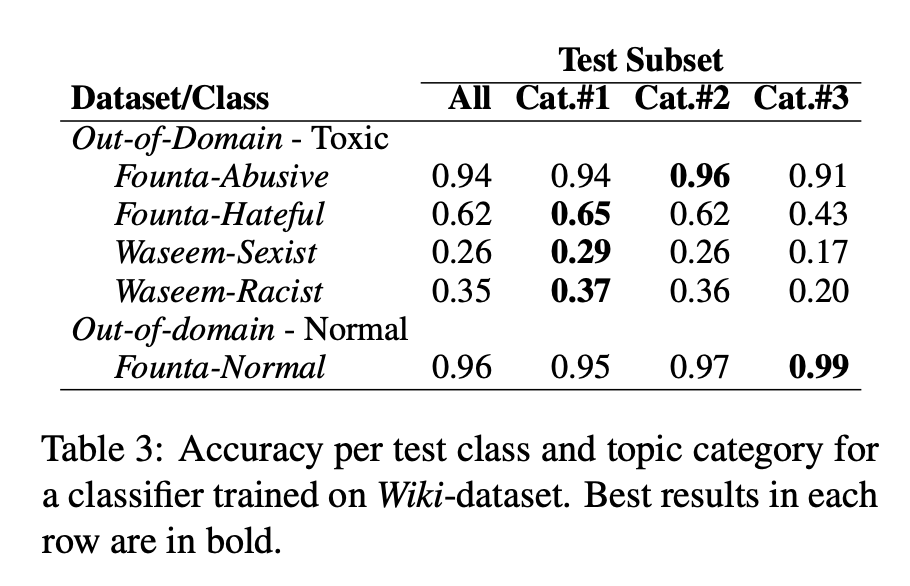
Results: The overall performance of the classifier on the Out-of-Domain test set is quite high: weighted macro-averaged F1 = 0.90.
- 저자들의 예상과 달리 전체적인 Out-of-Domain test 성능은 높은 편이었다. 그러나 Waseem 데이터셋의 Sexist, Racist class를 분류하는 데에는 Wiki-Dataset의 Toxic class로 훈련된 모델이 적합하지 않다는 사실을 확인했다.
# Formulation에 대한 논의
#key-observation
The impact of task formulation: From task formulations described in Section 3, observe that the Wiki-dataset defines the class Toxic in a general way. The class Founta-Abusive is also a general formulation of offensive behaviour. The similarity of these two definitions is reflected clearly in our results.
- 흥미로운 분석은 Formulation에 대한 것이다. 먼저 Wiki dataset의 Tosic class에 대한 정의는 다음과 같다 : ‘The class Toxic comprises rude, hateful, aggressive, disrespectful or unreasonable comments that are likely to make a person leave a conversation’.
- 그런데 이것이, Waseem 데이터셋의 Sexist, Racist class를 분류하기에는 다소 일반적인 정의라는 것이다.
# Impact of Data Size on Generalizability
#data-size
Observe that the average accuracies remain unchanged when the dataset’s size triples at the same class balance ratio. This finding contrasts with the general assumption that more training data results in a higher classification performance.
- 다음으로 저자는 또 흥미로운 포인트를 하나 더 확인했다.
- 만약 class의 비율이 변하지 않는다면 데이터의 크기가 커지더라도 정확도(
accuracy)는 변하지 않는다는 것이다. 이는 더 많은 훈련데이터가 항상 높은 분류 성능을 낸다는 general assumption과 반대되는 결과이다.
# Discussion
In the task of online abuse detection, both False Positive and False Negative errors can lead to significant harm as one threatens the freedom of speech and ruins people’s reputations, and the other ignores hurtful behaviour.
- False Positive와 False Negative는 표현의 자유를 위협할 수 있다.
We suggest evaluating each class (both positive and negative) separately taking into account the potential costs of different types of errors.
- 그리고 저자들은 각 class를 따로 평가하는 것을 제안했다.