Studying Generalisability Across Abusive Language Detection Datasets
Reference
Steve Durairaj Swamy, Anupam Jamatia, and Björn Gambäck. 2019. Studying Generalisability across Abusive Language Detection Datasets. In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), pages 940–950, Hong Kong, China. Association for Computational Linguistics.
# Previous Work
Abusive language detection has served as an umbrella term for a wide variety of subtasks. Research in the field has typically focused on a particular subtask: Hate Speech (Davidson et al., 2017; Founta et al., 2018; Gao and Huang, 2017; Golbeck et al., 2017), Sexism/Racism (Waseem and Hovy, 2016), Cyberbullying (Xu et al., 2012; Dadvar et al., 2013), Trolling and Aggression (Kumar et al., 2018a), and so on. Datasets for these tasks have been collected from various social media platforms, such as Twitter (Waseem and Hovy, 2016; Davidson et al., 2017; Founta et al., 2018; Burnap and Williams, 2015; Golbeck et al., 2017), Facebook (Kumar et al., 2018a), Instagram (Hosseinmardi et al., 2015; Zhong et al., 2016), Yahoo! (Nobata et al., 2016; Djuric et al., 2015; Warner and Hirschberg, 2012), YouTube (Dinakar et al., 2011), and Wikipedia (Wulczyn et al., 2017), with annotation typically carried out on crowdsourcing platforms such as CrowdFlower (Figure Eight)1 and Amazon Mechanical Turk.
- Abusive language detection에 대한 해외 연구 레퍼런스가 잘 설명되어 있다.
In the ‘OffensEval’ shared task (Zampieri et al., 2019b), the use of contextual embeddings such as BERT (Devlin et al., 2018) and ELMo (Peters et al., 2018) exhibited the best results.
- BERT가 등장하고 탐지 연구에 쓰이기 시작.
#key-observation
Generalisability of a model has also come under considerable scrutiny. Works such as Karan and Šnajder (2018) and Gröndahl et al. (2018) have shown that models trained on one dataset tend to perform well only when tested on the same dataset.
- 이 부분이 내 연구의 핵심과 관련이 깊다.
Additionally, Gröndahl et al. (2018) showed how adversarial methods such as typos and word changes could bypass existing state-of- the-art abusive language detection systems.
- “All you need is “love”: Evading hate speech detection” 논문 저자이다.
Fortuna et al. (2018) concurred, stating that although models perform better on the data they are trained on, slightly improved performance can be obtained when adding more training data from other social media.
- Fortuna et al. (2018) 연구도 있었구나. 다른 도메인에서 수집한 데이터를 더 추가해 훈련시키면 더 좋은 성능을 얻게 된다고 했었네. 지금의 일반화 가능성에 대한 논의가 여기에서 출발했다.
# Preliminary Feature and Model Study
However, fine-tuning was carried out on the mod- els’ hyper-parameters, such as sequence length, drop out, and class weights. Test and training sets were created for each dataset by performing a stratified split of 20% vs 80%, with the larger part used for training the models. The training sets were further subdivided, keeping 1/8 shares of them as separate validation sets during devel- opment and fine-tuning of the hyper-parameters.
- 그러나 시퀀스 길이, 드롭아웃 및 클래스 가중치와 같은 모델의 초 매개 변수에 대해 미세 조정이 수행되었다. 테스트 및 훈련 세트는 각 데이터 세트에 대해 20% 대 80%의 계층화된 분할을 수행하였고, 이후 더 큰 부분을 모델 훈련에 사용하였다. 훈련 세트는 더욱 세분화되어 하이퍼 파라미터의 개발 및 미세 조정 중에 1/8 공유를 별도의 검증 세트로 유지하였다.
- 모델 훈련에 대해서는 이렇게 설명하면 되겠다.
The best models used a learning rate of e−5 and batch size 32 with varying maximum sequence lengths between 60 and 70. Other parameters worth mentioning are the number of epochs and the Linear Warm-up Proportion.
- 모델 하이퍼파라미터의 경우에는 이렇게 표현하면 된다.
- 어라, 그런데 이거 보다보니 On Cross-Dataset Generalization in Automatic Detection of Online Abuse 이랑 설명이 똑같다.
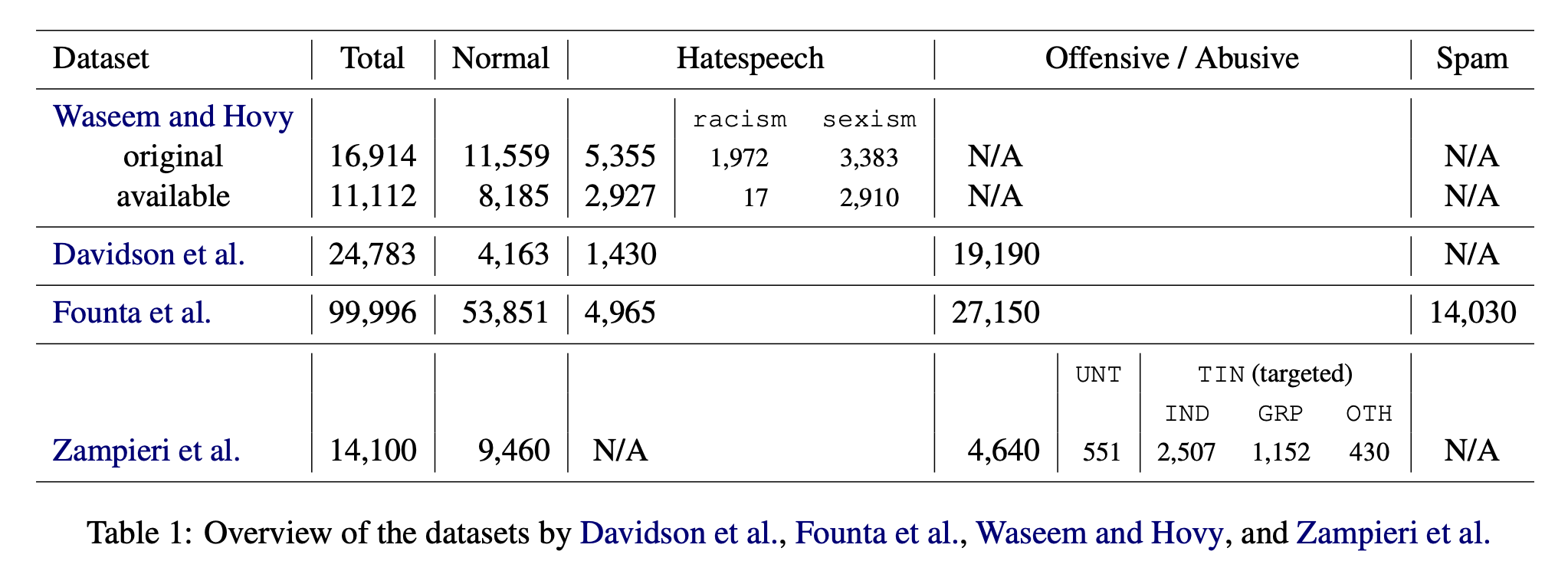
- 전체 데이터셋의 개요는 위 그림과 같다.
# Cross-Dataset Training and Testing
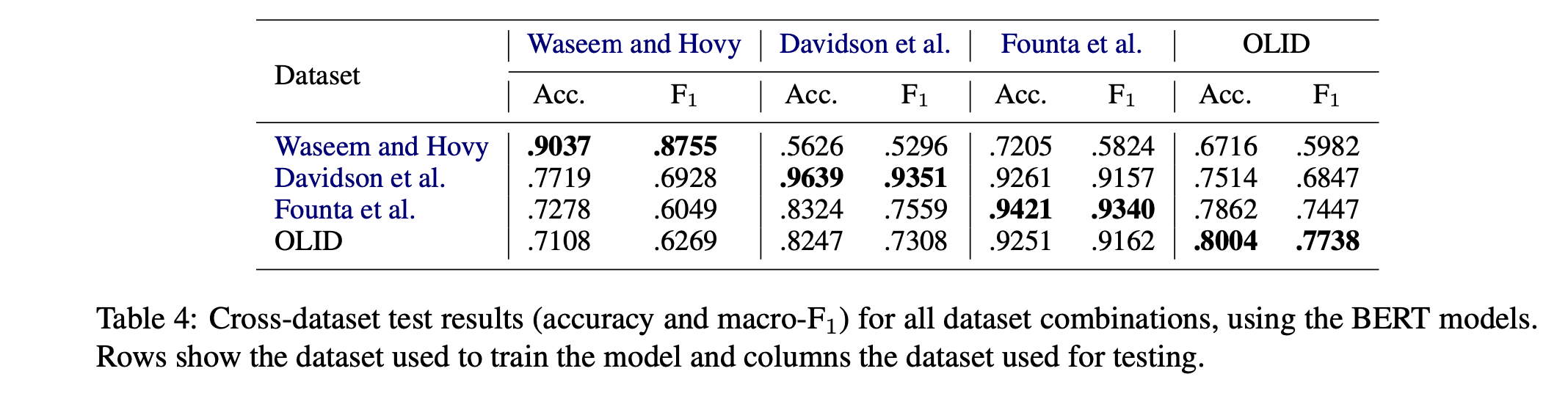
Considerable performance drops can be observed when going from a large training dataset to a small test set (i.e., Founta et al.’s results when tested on the Waseem and Hovy dataset) and vice versa. This is in line with a similar conclusion by Karan and Šnajder(2018).
- 큰 데이터셋부터 작은 데이터셋으로 갈 때 퍼포먼스 하락이 보인다.
The most interesting observation is that datasets with larger percentages of positive samples tend to generalise better than datasets with fewer positive samples, in particular when tested against dissimilar datasets. For example, we see that the models trained on the Davidson et al. dataset, which contains a majority of offensive tags, perform well when tested on the Founta et al. dataset, which contains a majority of non-offensive tags.
- 가장 흥미로운 관찰은 양성 샘플의 비율이 큰 데이터 세트가 특히 다른 데이터 세트에 대해 테스트할 때 양성 샘플이 적은 데이터 세트보다 더 잘 일반화되는 경향이 있다는 것이다. 예를 들어, 대다수의 공격 태그를 포함하는 Davidson 등 데이터 세트에 대해 훈련된 모델은 대다수의 비공격 태그를 포함하는 Founta 등 데이터 세트에서 테스트될 때 성능이 우수하다는 것을 알 수 있다.
- 내 연구도 이런 것이 있나 확인해보자.
# Discussion and Conclusion
Second, experiments showing that datasets with larger percentages of positive samples generalise better than datasets with fewer positive samples when tested against a dissimilar dataset (at least within the same platform, e.g., Twitter), which indicates that a more balanced dataset is healthier for generalisation.
An overall conclusion is that the data is more important than the model when tackling Abusive Language Detection.
- 데이터, 데이터! 결국은 데이터의 중요성을 말하며 이 논문은 끝을 낸다.